S -> TUd T -> a U -> bParsetræ:
S -> S -> S
/|\ /|\ /|\
T U d T U d T U d
| | |
a a b
S -> abd
S -> TUd T -> a U -> bParsetræ:
S
/|\
T TU T U |
| || | | |
abd -> abd -> abd -> a b d
S -> abd
For både Top-down- og Bottom-up-parsing gælder der en række Design-kriterier: |
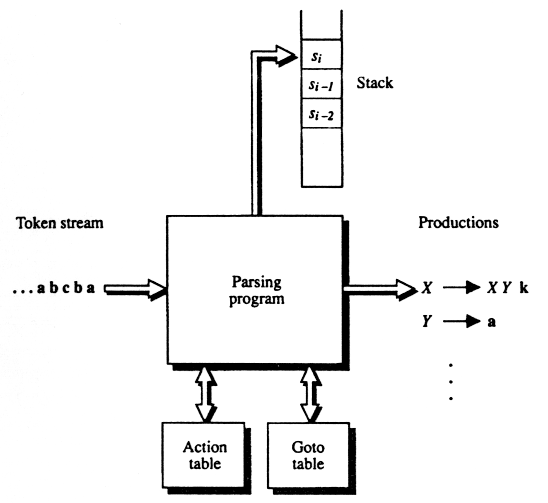
| Figur 6-3: LR shift-reduce parser |
| Parse-type | Forkortelse |
| Canoncial LR(k) | LR(k) |
| Lookahead LR(k) | LALR(k) |
| Simple LR(k) | SLR(k) |
saetning : {printf("(tildeling)\n");} ID '=' udtryk
| ID '(' udtryk ')'
| VAR_ERKLAER
; |
| Eksempel 6-1: Uddrag af tidlig version af saetning-grammatik |